

Audio-visual modeling of human activity
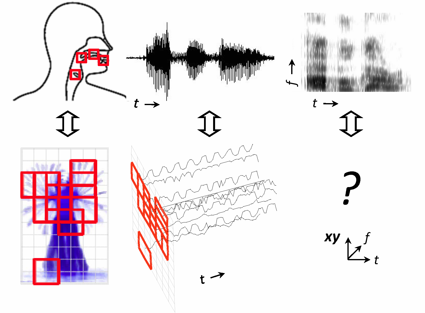 |
There are several analogies between activity and speech signals with regard to the way they are
generated, propagated, and perceived. Despite all the “acting apparatus” being directly visible,
there is little in the way of research exploring the temporal signals emitted from body parts for
activity recognition. We propose a novel action representation, the action spectrogram,
which is inspired by a common spectrographic representation of speech. Different from sound spectrogram,
an action spectrogram is a space-time-frequency representation which characterizes the short-time spectral
properties of body parts’ movements. We transform an activity sequence into the occurrence likelihood series of
action associated space-time interest points (STIP); therefore, activities are recognized by not only
local video content but also occurrence likelihood spectra of action associated STIP.
Related publication
- Chia-Chih Chen and J. K. Aggarwal, Modeling Human Activities as Speech,
IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Colorado Springs, USA, Jun. 2011 (to appear). [BibTex][Video][Supplementary]
Low-resolution human-vehicle interaction recognition
 |
We propose a novel framework to recognize human-vehicle
interactions from aerial video. In this scenario,
the object resolution is low, the visual cues are vague, and
the detection and tracking of objects are less reliable as a
consequence. To address these issues, we present a temporal
logic based approach which does not require training
from event examples. At the low-level, we employ dynamic
programming to perform fast model fitting between
the tracked vehicle and the rendered 3-D vehicle models.
At the semantic-level, given the localized event region of
interest (ROI), we verify the time series of human-vehicle
relationships with the pre-specified event definitions in a
piecewise fashion.
Related publication
- Jong Taek Lee*, Chia-Chih Chen*, and J. K. Aggarwal, Recognizing Human-Vehicle Interactions from Aerial Video without Training,
Workshop of Aerial Video Processing in conjunction with CVPR (WAVP), Colorado Springs, USA, Jun. 2011. *Equal contribution authorship. [BibTex]
Low-resolution human action recognition
 |
 |
 |
 |
 |
 |
 |
 |
 |
Recognition of human actions from a distant view is a
challenging problem in computer vision.
The available visual cues are particularly sparse and vague under this
scenario. We proposed an action descriptor which is composed of time
series of subspace projected histogram-based features. Our descriptor
combines both human poses and motion information and performs feature
selection in a supervised fashion. Our method has been tested on
several public datasets and achieves very promising accuracy.
Related publications
- Chia-Chih Chen and J. K. Aggarwal, Recognizing Human Action from a Far Field of View,
- M. S. Ryoo, Chia-Chih Chen, J. K. Aggarwal, and Amit Roy-Chowdhury, An Overview of Contest on Semantic Description of Human Activities (SDHA) 2010,
- Chia-Chih Chen, M. S. Ryoo, and J. K. Aggarwal, UT-Tower Dataset: Aerial View Activity Classification Challenge,
IEEE Workshop on Motion and Video Computing (WMVC), Snowbird, USA, Dec. 2009. [BibTex]
International Conference on Pattern Recognition (ICPR) Contests, Istanbul, Turkey, Aug. 2010. [BibTex]
2010. [BibTex]
Kinect applications - human detection
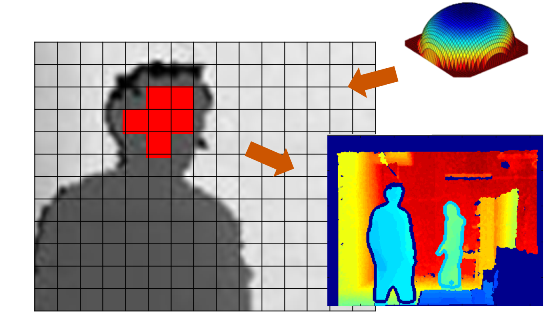 |
In this paper,
we present a novel human detection method using depth
information taken by Kinect for Xbox 360. We propose
a model based approach, which detects humans using a
2D head contour model and a 3D head surface model. We
propose a segmentation scheme to segment humans from the
surroundings and extract the complete contours of the
figures based on the detected ROI. We also explore the
tracking algorithm based on detection results. Our
method is tested on a database taken by Kinect in
our lab and presents superior results.
Related publication
- Lu Xia, Chia-Chih Chen, J. K. Aggarwal, Human Detection Using Depth Information by Kinect,
Workshop on Human Activity Understanding from 3D Data in conjunction with CVPR (HAU3D), Colorado Springs, USA, Jun. 2011. [BibTex]
Kinect applications - human action recognition
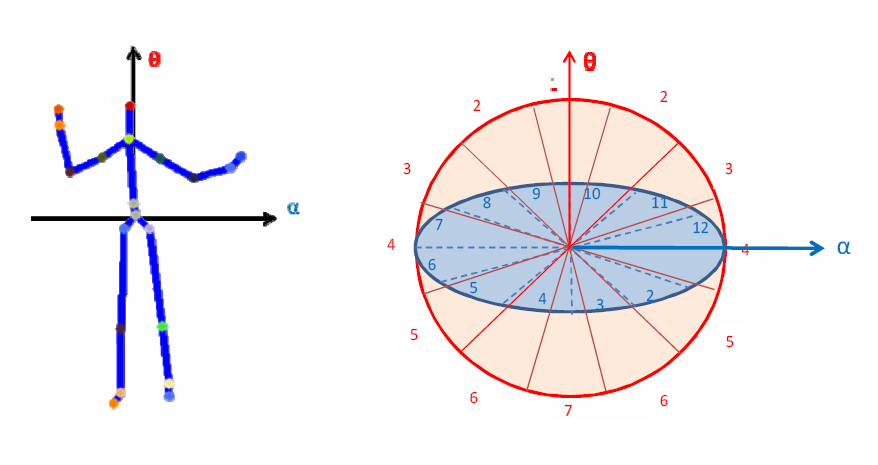 |
We present a novel approach for human
action recognition with histograms of 3D joint locations
(HOJ3D) as a compact representation of postures. We
extract the 3D skeletal joint locations from Kinect depth
maps using Shotton et al.’s method. The HOJ3D
computed from the action depth sequences are reprojected
using LDA and then clustered into k posture visual words,
which represent the prototypical poses of actions. The
temporal evolutions of those visual words are modeled by
discrete hidden Markov models (HMMs). In addition, due
to the design of our spherical coordinate system and the
robust 3D skeleton estimation from Kinect, our method
demonstrates significant view invariance on our 3D action
dataset.
Related publication
- Lu Xia, Chia-Chih Chen, J. K. Aggarwal, View Invariant Human Action Recognition Using Histograms of 3D Joints,
Workshop on Human Activity Understanding from 3D Data in conjunction with CVPR (HAU3D), Rhode Island, USA, Jun. 2012. [BibTex]
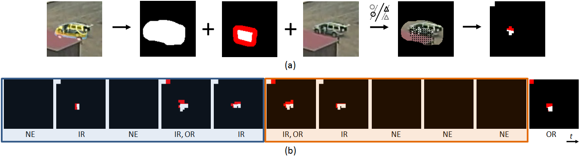
Detection of object abandonment
Public security is a crucial issue in our world today.
In this work, we describe a smart threat detection system that
captures, exploits and interprets the temporal flow of sub-events
related to the abandonment of an object. Our representational framework
applies temporal interval logic to define the relationships between
actions, events, and their effects. An event is defined as having
occurred if and only if a given sequence of observations matches the
formal event representation and meets the pre-specified temporal
constraints.
Related publications
- M. Bhargava, Chia-Chih Chen, M. S. Ryoo, and J. K. Aggarwal, Detection of Object Abandonment Using Temporal Logic,
- M. Bhargava, Chia-Chih Chen, M. S. Ryoo, and J. K. Aggarwal, Detection of Abandoned Objects in Crowded Environments,
Journal of Machine Vision and Applications (MVA), 20(5):271-281, Jun. 2009. [BibTex]
IEEE International Conference on Advanced Video and Signal based Surveillance (AVSS), London, UK, Sep. 2007. [BibTex]
Human cast shadow removal
 |
The success in human shadow removal leads
to the accurate recognition of activities and the robust
tracking of people. We present a shadow
removal technique which effectively eliminates human
shadow cast from an unknown direction of light source.
A multi-cue shadow descriptor is proposed to characterize
the distinctive properties of shadow. We employ
a 3-stage process to detect then remove shadow. Our
algorithm further improves the shadow detection accuracy
by imposing the spatial constraint between the
foreground subregions of human and shadow.
Related publication
- Chia-Chih Chen and J. K. Aggarwal, Human Shadow Removal with Unknown Light Source,
International Conference on Pattern Recognition (ICPR), Istanbul, Turkey, Aug. 2010. [BibTex]
Recognition of box-like objects
 |
In this work, we propose a template-based algorithm
for recognizing box-like objects. Our technique is invariant to scale, rotation
and translation as well as robust to patterned surfaces and moderate occlusions.
We reassemble box-like segments from an over-segmented image. The shapes and inner edges
of the merged box-like segments are verified seprartly with the corresponding templates.
We formulate the process of template matching into an optimization problem, and propose a
combined metric to evaluate the similarity.
Related publication
- Chia-Chih Chen and J. K. Aggarwal, Recognition of Box-like Objects by Fusing Cues of Shape and Edges,
International Conference on Pattern Recognition (ICPR), Tampa, USA, Dec. 2008. [BibTex]
Video background initialization
 |
Background subtraction is an essential element in most object tracking and video surveillance systems.
The success of this low-level processing step is highly dependent on the quality of the background model maintained.
We present a background initialization algorithm which identifies stable intervals of intensity values at each pixel, and determines which
interval is most likely to display background. Our method is adaptive to the scale of
foregound motion and is able to equalize the uneven effect caused by different object depths. Our method achieves promising results even
with complex foreground contents.
Related publication
- Chia-Chih Chen and J. K. Aggarwal, An Adaptive Background Model Initialization Algorithm with Objects Moving at Different Depths,
IEEE International Conference on Image Processing (ICIP), San Diego, USA, Oct. 2008. [BibTex]